
Оптимизация СХД с помощью DCAP-системы

Несмотря на то, что решение системы класса DAG/DCAP нацелены в первую очередь на сотрудников информационной безопасности, применять её можно и для решения задач ИТ-департамента: поиск «пропавших» файлов и каталогов пользователей, миграция данных, удаление дубликатов, выявление неиспользуемых информации, анализ размера директорий и общего роста занимаемого объёма за заданный промежуток времени. В сегодняшней статье мы рассмотрим задачи по оптимизации СХД с точки зрения управления устаревшими и продублированными данными, а также отслеживание динамики роста данных.
Неиспользуемые данные
Так как система DAG/DCAP ежедневно сканирует файловые хранилища и собирает метаданные обо всех файлах и папках, с её помощью можно строить отчёты по неиспользуемой информации на базе меток даты модификации (Modify date) сразу после установки системы и первого сканирования. Однако важно понимать, что данная информация не является точной, так как изменение метки Modify date происходит только при модификации файла или папки, но не его чтения. А так как большинство производителей СХД отключают по умолчанию модификацию меток даты доступа (Access date) при открытии самого файла ради производительности (например, Microsoft по умолчанию отключил данную опцию начиная с Windows Server 2008R2), то дать 100% гарантию отсутствия обращений к объекту только на базе метки Modify date нельзя. Другими словами, мы сможем лишь построить общее представление о масштабах залежавшейся информации, некую «среднюю температуру по больнице».
С другой стороны, благодаря сбору всех действий любых учётных записей на файловых хранилищах с сохранением их во внутреннюю базу данных, DAG/DCAP по прошествии некоторого времени может сказать, к каким объектам точно не было никаких обращений. Данную информацию можно получать в виде отчётов с сортировкой по размеру, либо в виде регулярных подписок на почту или в сетевую папку:

В этом случае уже можно смело брать данные директории или файлы и перемещать их на более медленные или дешевые СХД, или например в архив в виде ленточных накопителей, высвободив дисковую подсистему для новой информации без необходимости дозакупки новых дисковых полок. Причём перемещать можно как вручную силами ИТ отдела, так и используя модуль переноса данных – в нём можно гибко указать критерии выборки данных (определённые папки, типы файлов, количество дней без обращений и т. д.) и настроить расписание.
Поиск дубликатов
Благодаря анализу каждого файла и подсчёту хэш-сумм, система способная выявлять бинарные копии файлов поверх всех подключённых к наблюдению хранилищ. В этом случае легко выявить дубликаты файлов не только в разных папках в пределах одного файлового ресурса, но и на разных хранилищах, что обычно не компенсируется функциями дедупликации на самих серверах приложений или СХД.
В результате получается список всех дубликатов на всех серверах, который можно аналогично либо выгрузить и отдать в отдел ИТ на ручную проработку, либо использовать модуль переноса для их автоматического удаления:

Самым распространённым результатом таких работ является быстрое высвобождение места посредством удаления самых объёмных файлов-дубликатов. Однако ещё можно отсортировать отчёт по количеству дублей и выявить наиболее популярные шаблоны файлов и документов, присутствующими тысячами и десятками тысяч копий.
Динамика роста данных
Обладая ежедневными данными о размерах каждого объекта на файловых хранилищах, система может контролировать динамику роста определённых директорий (наиболее быстрорастущие папки) или хранилища в целом с прогнозом его полного заполнения в оставшихся днях:

Это позволяет заранее планировать необходимое расширение или работы по оптимизации СХД с прогнозируемыми затратами, а также оперативно выявлять причины резко заканчивающегося места на сервере и пользователей, загрузившим на него наибольшее количество информации.
Управление данными
Как упоминалось ранее, система предоставляет специальный модуль для автоматического управления информацией на базе заданных политик. В его основе лежит принцип выборки данных по гибким критериям-фильтрам и требуемому действию с ними. Как следствие, модуль позволяет решать следующие задачи:
- автоматически удалять дубликаты в указанных папках / хранилищах;
- перемещать неиспользуемую за заданный период времени информацию на более дешёвые СХД или ленточные накопители;
- чистить раз в день или неделю папки общего обмена;
- перемещать файлы с критичными данными из мест их некорректного расположения (включая общедоступные каталоги) в закрытую зону карантина.
Автоматизация таких рутинных операций позволяет экономить время сотрудников ИТ и ИБ департаментов, а настройка таких политик достаточно прямолинейна и не составляет сложности даже для человека, который ни разу не пользовался системами данного класса. К примеру, очень просто настроить правило переноса документов с коммерческой тайной из всех общедоступных каталогов одного из файловых серверов:
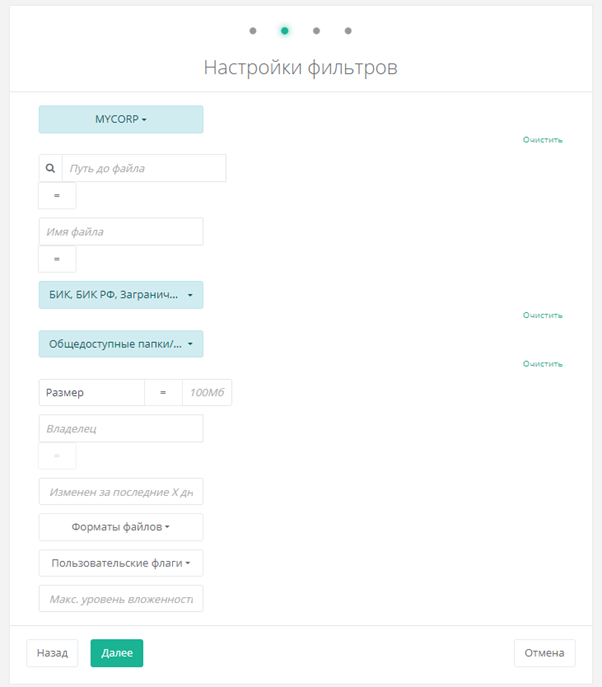
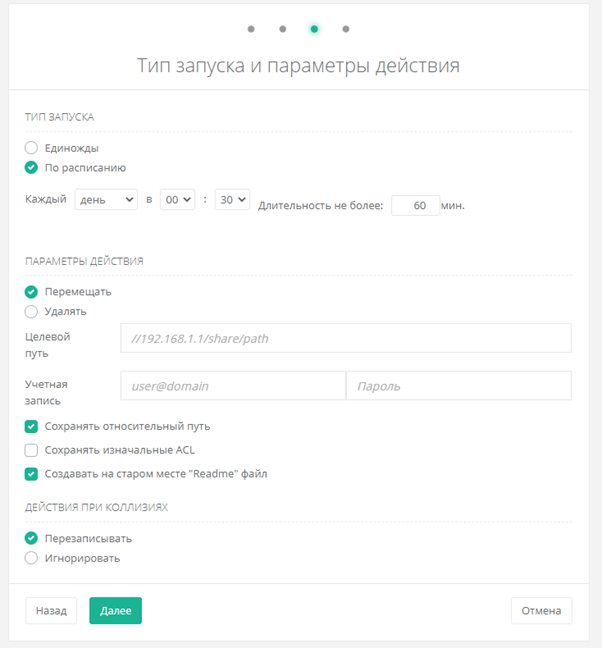
В дальнейшем лишь потребуется указать расписание работы политики, путь для переноса данных с учётной записью и задать дополнительные опции – например, сохранение структуры расположения или генерацию текстового файла на месте старых данных для уведомления пользователей о произведённом переносе:
DCAP для ИТ отдела
Несмотря на ориентированность DCAP систем на обеспечение безопасности данных, накопленную системой информацию можно использовать и для решения ИТ-задач: поиск и удаление дубликатов, идентификация и перенос неиспользуемых документов, чистка каталогов общего доступа, прогнозирование заполняемости файловых хранилищ, выявление быстрорастущих папок с идентификацией сотрудников, совершивших данные действия. Всё это позволяет оптимизировать расходы на СХД и высвободить время сотрудников на другие задачи посредством автоматизации рутинных действий.
Преимущества от внедрения DAG/DCAP «Спектр»
Решение «Спектр» класса DAG/DCAP позволяет решать все вышеописанные задачи, а также отслеживать, анализировать и автоматически реагировать на нестандартное поведение любой из учётных записей, выявлять существующие риски в инфраструктуре, контролировать процесс их сокращения с предоставлением инструментария по автоматизации и создавать собственные политики безопасности в зависимости от требований бизнеса.
Наша команда также готова провести бесплатный аудит рисков вашей инфраструктуры с целью выявления существующих рисков и проблемных мест и по его результатам предоставить полноценный отчёт.

Иван Дудоров, руководитель группы поддержки продаж компании «Сайберпик»
